
Introduction
Healthcare fraud is draining tens of billions of dollars annually from U.S. healthcare programs. According to CMS, Medicare and Medicaid improper payments totaled $91.26 billion in FY2025: Medicare Fee-for-Service accounted for $28.83 billion, Medicare Advantage $23.67 billion, and Medicaid $37.39 billion. While not all improper payments represent fraud — many stem from billing errors or insufficient documentation — the scale reveals a systemic vulnerability that reactive auditing alone cannot address.
Healthcare organizations are responding by turning to data mining — shifting from reactive auditing to proactive fraud detection. This shift is especially urgent for rural health systems managing lean operations and limited compliance staff.
Rural hospitals are particularly vulnerable to fraud exposure: smaller teams, less sophisticated billing infrastructure, and heavy dependence on a few high-volume providers create concentrated risk — compounded by workforce shortages and service closures.
TL;DR
- Data mining flags anomalies in billing records, diagnosis codes, and provider patterns to detect fraud, waste, and overpayment
- Key techniques include association rule mining, anomaly detection, clustering, and machine learning classifiers
- Common fraud patterns detected include upcoding, duplicate billing, phantom procedures, and atypical provider-patient-service relationships
- AI-powered data mining can achieve up to 90% detection accuracy compared to 50-60% for traditional manual audits
- Effective implementation depends on clean, connected data infrastructure — a persistent gap for rural and underserved organizations
What Is Healthcare Claim Data Mining?
Healthcare claim data mining is the systematic application of statistical algorithms and machine learning techniques to large volumes of claims records — surfacing patterns, anomalies, and associations that indicate fraud, billing errors, or waste. Manual audits review a small sample of claims. Data mining analyzes entire populations, catching statistical outliers and unusual relationships that human reviewers miss.
What healthcare claim data actually consists of:
Healthcare claim data is the structured record submitted by providers to payers for reimbursement. According to CMS billing standards, each claim contains:
- Provider identifiers (NPI numbers)
- Diagnosis codes (ICD-10-CM)
- Procedure codes (CPT/HCPCS)
- Service modifiers
- Payment amounts
- Dates of service
- Patient demographics
- Utilization day counts
- Beneficiary information
This structured, coded data is uniquely suited for pattern analysis because every element is standardized, making it possible to compare millions of claims across providers, geographies, and time periods.
Three Main Application Modes
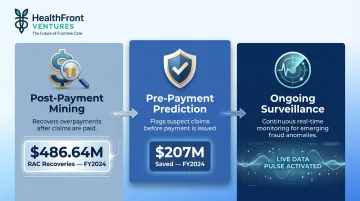
Post-payment data mining — Recovers overpayments after claims have been paid. The Recovery Audit Contractor (RAC) program identified $486.64 million in overpayments in FY2024 using post-payment analytics.
Pre-payment prediction — Flags suspect claims before payment is sent. CMS's Fraud Prevention System saved $207.0 million in FY2024 through automated pre-payment edits that block suspicious claims before they're processed.
Ongoing surveillance — Continuously monitors claims populations for emerging anomalies. Unified Program Integrity Contractors (UPICs) apply this approach to investigate provider fraud patterns. Notably, 90% of UPIC Medicaid investigations in FY2024 relied on T-MSIS data analysis.
Why Claim Data Mining Is Critical for Healthcare Fraud Prevention
Fraud, Waste, and Abuse (FWA) in healthcare is not a single problem but a spectrum requiring different detection approaches:
- Fraud — intentional deception for financial gain (e.g., billing for services not rendered, identity theft, kickback schemes)
- Waste — overuse of resources without clear clinical benefit (e.g., ordering unnecessary procedures or tests)
- Abuse — practices inconsistent with accepted billing standards but may not be intentional (e.g., consistent overbilling for complexity)
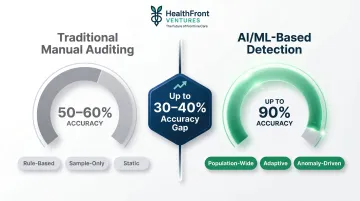
Manual audits and rule-based query systems are insufficient at scale. CMS reported a 6.55% improper payment rate for Medicare FFS in FY2025, yet traditional random auditing captures only a small fraction of those errors.
Machine learning-based approaches achieve up to 90% detection accuracy in high-income healthcare settings — compared to 50-60% for traditional auditing methods.
Rural Healthcare's Unique Vulnerability
Rural healthcare organizations face amplified fraud exposure:
- Smaller administrative teams with limited compliance oversight capacity
- Less sophisticated billing infrastructure and lower technology adoption
- Greater dependence on a few high-volume providers, making anomaly detection harder
- Reduced capacity for internal audits due to workforce shortages
Rural hospitals are especially vulnerable to clinical workforce shortages, with nearly an 8% decline in rural obstetric access between 2010 and 2022. When frontline clinical staffing is stretched thin, compliance and billing oversight absorb the same cuts — leaving rural organizations with fewer resources to detect and recover overpayments.
Key Operational and Financial Benefits
For rural healthcare organizations, claim data mining delivers measurable operational returns:
- Higher fraud-flagging precision, directing auditor time to the most suspect claims rather than random samples
- Detection of overpayments that rule-based systems have already missed
- Cost-based recovery prioritization (highest-dollar anomalies first) rather than error-count minimization
- Identification of systemic billing irregularities that point to contract programming errors or provider-level schemes
- Adaptive learning that keeps pace as fraud tactics evolve
How Healthcare Claim Data Mining Works – Step by Step
Most claims fraud is not detectable at the individual transaction level. Patterns only emerge when you look across multiple claims, providers, and time periods — which is why this process requires systematic data aggregation and cross-claim analysis. The five steps below walk through how that works in practice.
Step 1 – Define the Detection Objective
Specify the type of anomaly being targeted:
- Duplicate payments (same service billed multiple times)
- Upcoding (billing for higher-complexity services than delivered)
- Phantom billing (billing for services never rendered)
- Provider collusion (coordinated billing schemes)
- Contract misapplication (systematic payment errors from programming mistakes)
Each objective requires different feature selection and thresholds. For example, detecting upcoding requires comparing a provider's procedure code distribution against peer providers treating similar patient populations.
Step 2 – Collect and Integrate Claims Data
Required data inputs include:
- Inpatient and outpatient claims
- Provider NPI records
- Diagnosis and procedure code mappings (ICD-10-CM, CPT, HCPCS)
- Payment amounts and remittance details
- Utilization counts (visit frequency, length of stay)
Data fragmentation is the most common obstacle at this stage — particularly for rural or smaller health organizations that lack integrated data infrastructure. Claims data often sits across separate billing systems, EHRs, and payer platforms that don't communicate with each other.
Step 3 – Preprocess and Encode the Dataset
Essential preprocessing steps:
- Remove redundant or irrelevant features
- Encode categorical variables (provider IDs, diagnosis codes, geographic identifiers)
- Normalize payment amounts to enable cross-provider comparison
- Handle missing data and outliers
- Create derived features (e.g., average payment per procedure code, utilization rate)
Skipping this step produces noisy rules and high false-positive rates. Well-preprocessed data is what allows anomaly detection algorithms in Step 4 to distinguish genuine fraud signals from statistical noise.
Step 4 – Apply Mining and Anomaly Detection Techniques
Leading methodologies use a two-stage approach:
Stage 1 – Association Rule Mining: Apply algorithms (such as Apriori) to extract frequent co-occurrence patterns across patient-provider-service combinations. For example, identify which diagnosis codes typically appear with which procedure codes and payment amounts.
Stage 2 – Unsupervised Anomaly Detection: Apply algorithms like Isolation Forest, Cluster-Based Local Outlier Factor (CBLOF), or One-Class Support Vector Machine (OCSVM) to identify which patterns fall outside expected behavior. Provider-level anomaly detection using unsupervised techniques has achieved AUC scores up to 0.974 on private insurance datasets.

Step 5 – Interpret, Validate, and Act on Findings
Algorithmic flags are not final determinations. Subject matter experts must:
- Review findings to confirm fraud confidence
- Prioritize recoveries using cost-based metrics (coverage and dollar impact)
- Validate anomalies against clinical and billing norms
- Investigate rules flagged by multiple algorithms (higher confidence than single-algorithm flags)
The OIG Medicare compliance audit of St. Joseph's Hospital Health Center — which identified $14.7 million in overpayments — demonstrates how auditors use data mining techniques to flag high-risk providers for detailed review.
Fraud Patterns That Healthcare Claim Data Mining Uncovers
Upcoding and Procedure Manipulation
Data mining identifies providers that consistently bill for higher-complexity procedure codes than peer providers treating similar patient populations. For example, if Provider A bills 80% of office visits at the highest evaluation and management (E/M) level while peers bill only 30% at that level, the pattern suggests upcoding.
Algorithms also detect when procedure codes frequently co-occur with unusually high payment amounts relative to diagnosis severity—a red flag for code manipulation.
Duplicate and Phantom Billing
Cross-claim pattern analysis detects:
- The same service billed multiple times across different dates or claim IDs
- Claims split inappropriately to avoid contractual thresholds (a manipulation pattern documented in real recovery cases)
- Services billed for patients who have no record of receiving them
The FBI identifies duplicate billing as one of the most common provider fraud schemes, often invisible without automated cross-claim analysis.
Atypical Provider-Patient-Service Relationships
Duplicate billing operates at the transaction level—but fraud also hides in the relationships between patients, physicians, and service providers. Association rules capture expected behavioral norms across that triangle, and anomalies include:
- A diagnosis code rarely associated with a given procedure appearing repeatedly for one provider
- Patient utilization patterns (visit frequency, stay duration) deviating significantly from cohort norms
- Unusually high volume of services per patient compared to peer providers
- Geographic mismatches (provider billing for services in locations where they don't practice)
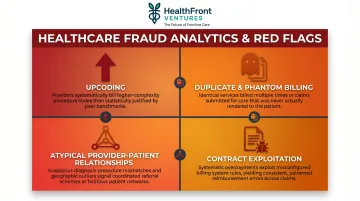
Contract and Billing System Exploitation
System-level programming errors can trigger systematic overpayments across hundreds of claims before anyone notices. Data mining surfaces these patterns through cases involving:
- Incorrect discount application
- Per-diem clause misinterpretation
- Duplicate payment processing from system bugs
CMS's FY2024 program integrity efforts demonstrate how analytics-driven enforcement recovered $26.3 billion total, with systematic overpayment detection accounting for a major share of those recoveries.
How HealthFront Ventures Can Help Rural Healthcare Organizations
The foundational prerequisite for any effective claim data mining program is clean, connected, and structured healthcare data. Rural health organizations often lack the in-house capacity to build and maintain this infrastructure—a critical gap that limits their ability to detect fraud, recover overpayments, and protect reimbursement integrity.
HealthFront Ventures builds AI-native data infrastructure specifically for rural healthcare. Its AI-Native HCP Workforce Data Warehouses and Lakes give rural health systems the data foundation needed to move toward analytics-ready claims environments.
Unlike general-purpose healthcare analytics platforms, HealthFront's infrastructure integrates Medicare and Medicaid claims data with NPI-level provider records and geographic identifiers—purpose-built for the rural context, not retrofitted from urban-market tools.
HealthFront Baseline™: Benchmarking Data Posture
Launching in Q1 2026, HealthFront Baseline™ provides FY25 Baseline Data Metrics and a Rural County Quality Measure—a benchmarking tool that helps organizations understand their data posture before implementing fraud detection workflows. The service delivers:
- Four quantitative metrics calibrated for rural healthcare provider workforce management
- One rural county quality measure tracking performance across geographic areas
- Analytics-ready datasets for gap analysis, RHT performance measurement, and value-based care program design
- Outsourced data infrastructure eliminating the need for custom builds
That data posture then becomes the operational foundation for fraud detection and compliance work. Rural healthcare organizations with structured infrastructure in place are better positioned to:
The Path Forward for Rural Health Systems
- Implement claims data mining and reduce FWA exposure
- Protect reimbursement integrity through proactive anomaly detection
- Redirect recovered funds toward provider retention and patient care
- Meet compliance requirements without expanding administrative headcount
For rural health systems navigating thin margins and provider shortages, getting the data infrastructure right is what makes every downstream initiative—from fraud recovery to workforce planning—actually executable.
Frequently Asked Questions
What is healthcare claim data?
Healthcare claim data is the structured record submitted by providers to payers for reimbursement, encompassing diagnosis codes (ICD-10-CM), procedure codes (CPT/HCPCS), provider identifiers (NPI), payment amounts, dates of service, and patient utilization details—all of which serve as the raw material for data mining analysis.
What are the 4 stages of data mining?
Healthcare claims data mining follows four stages:
- Data collection and preparation — gathering and cleaning claims records
- Pattern discovery — applying algorithms to find associations or anomalies
- Result evaluation — validating findings against domain knowledge
- Action and deployment — using insights to recover overpayments or prevent future errors
What is an example of data mining in healthcare?
Applying association rule mining to Medicare inpatient data to detect that a specific combination of diagnosis code, unusually short patient stay, and high payment amount consistently co-occurs for one provider—flagging it for auditor review as a potential upcoding pattern.
Is data mining covered by HIPAA?
HIPAA does not prohibit data mining, but any protected health information (PHI) involved must be either de-identified per 45 CFR 164.514 or covered by a Business Associate Agreement. Access controls, encryption, and audit trails are required throughout the process.
What is the difference between healthcare fraud, waste, and abuse?
Each term describes a distinct billing problem:
- Fraud — intentional deception for financial gain, such as billing for services not rendered
- Waste — overuse of resources without clear clinical benefit, such as unnecessary tests
- Abuse — billing practices inconsistent with accepted standards that may not be intentional, such as consistent overbilling for visit complexity
All three are detectable through claims data mining.
How does AI improve healthcare claims fraud detection?
AI—particularly unsupervised machine learning algorithms like Isolation Forest and CBLOF—can scan millions of claims simultaneously, identify statistically anomalous patterns invisible to rule-based systems, and continuously adapt as fraud tactics evolve. Research demonstrates AI produces far higher detection precision (up to 90% accuracy) than manual audits or static query tools (50-60% accuracy).


