
Introduction
Healthcare organizations are drowning in data—and most haven't built the infrastructure to use it. Healthcare generates approximately 30% of the world's data volume, growing at a compound annual rate of 36%—six points faster than manufacturing and ten faster than financial services.
EHR records, lab results, workforce credentialing data, SDOH indicators, and unstructured clinical notes pour into systems daily. Choosing the wrong storage structure turns that data flood into fragmented silos, slower decisions, and compliance exposure.
For rural healthcare organizations, the pressure is compounded. Limited IT resources, expanding regulatory demands under state-level Rural Health Transformation programs, and the push to deploy AI-driven workforce analytics all hit at once—against budgets that can't absorb a costly infrastructure mistake.
Poor data exchange costs the U.S. healthcare system over $30 billion annually, and nearly 70% of hospitals struggle to exchange patient information with other systems. For rural organizations operating with less margin for error, the architecture decision matters more, not less.
That's what this guide is for. It breaks down data lakes, data warehouses, traditional databases, and the emerging data lakehouse architecture—so you can match the right storage foundation to your organization's analytics goals, compliance requirements, and real-world capacity.
Key Takeaways
- Data lakes store raw data in any format with schema-on-read flexibility, making them well-suited for AI/ML workflows and diverse data ingestion
- Data warehouses organize pre-processed, structured data for fast and reliable BI reporting
- Traditional databases handle transactional operations but fall short for large-scale analytics
- Data lakehouses combine lake flexibility with warehouse governance—the most versatile modern option
- Your best fit depends on data volume, analytics goals, compliance requirements, and build-vs-outsource preferences
Healthcare Data Lake vs. Other Structures: Quick Comparison
| Dimension | Data Lake | Data Warehouse | Traditional Database | Data Lakehouse |
|---|---|---|---|---|
| Data Structure | Raw, unprocessed; schema-on-read (structure applied at query time) | Structured, pre-processed; schema-on-write (structure defined before load) | Highly structured; optimized for row-level transactions | Hybrid; flexible ingestion with structured querying layer |
| Data Types Supported | Structured, semi-structured, unstructured (EHR, HL7/FHIR, physician notes, imaging) | Structured only (claims, lab results, billing records) | Structured only (patient records, scheduling, billing) | All types—structured, semi-structured, unstructured |
| Scalability | Horizontal; scales to petabytes cost-effectively | Vertical; expensive at scale; limited by warehouse capacity | Vertical; struggles with high-volume analytics workloads | Horizontal; inherits lake scalability with warehouse performance |
| Analytics Readiness | Batch processing, AI/ML model training, exploratory analysis | BI reporting, dashboards, regulatory submissions | Real-time transactional queries; not designed for analytics | Supports both AI/ML and BI workloads from a single platform |
| HIPAA Compliance Complexity | Requires governance tooling (Lake Formation, tagging, access controls) | Built-in structure simplifies compliance; column-level security | Database-level security; limited governance for diverse data | Governance layer built in; reduces compliance overhead vs. lakes |
| Best Fit Use Case | Diverse, high-volume data ingestion for AI and predictive analytics | Fast, reliable reporting on structured data with minimal transformation | Operational systems (scheduling, billing, EHR transactions) | Scalable ingestion, governed analytics, and AI/ML in one platform |
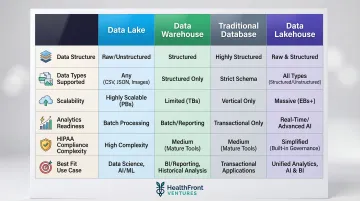
Key Insight: The right choice depends on what you're building toward. For rural healthcare organizations running AI-driven workforce analytics — processing provider retention data, HL7/FHIR feeds, and county-level health metrics — a data lake or lakehouse typically outperforms the alternatives. Warehouses and traditional databases remain valuable for structured reporting and operational transactions, but they weren't designed for the data diversity that rural HCP workforce planning demands.
What is a Healthcare Data Lake?
A healthcare data lake is a centralized repository that ingests and stores data in its native format—structured (claims, lab results), semi-structured (HL7/FHIR messages), and unstructured (physician notes, imaging files, workforce credentialing documents)—without requiring pre-transformation. Unlike traditional databases or warehouses that enforce a rigid schema upfront, data lakes use a "flat architecture and object storage" that saves data "as is, without the need to impose a schema up front."
Schema-on-Read Advantage
The defining characteristic of a data lake is schema-on-read: data is stored first and structured when queried. This contrasts with data warehouses, which require schema-on-write—meaning you must define how data will be organized before loading it.
For healthcare organizations, this distinction is critical. As new data streams emerge—SDOH indicators, workforce retention metrics, patient-generated health data—lakes adapt without requiring infrastructure overhauls. You can onboard new data sources in days rather than months, then experiment with different analytical approaches without predefined constraints.
Core Operational Benefits
Healthcare data lakes break down silos across EHRs, billing systems, and workforce platforms. They enable:
- Train AI and machine learning models on diverse, raw datasets without preprocessing bottlenecks
- Combine clinical, claims, and social determinant data for population health analytics
- Track credentialing, retention, and recruitment metrics at scale across provider workforce platforms
- Integrate multi-source patient data for real-time risk stratification and care coordination
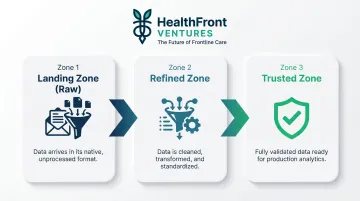
However, poorly governed data lakes become "data swamps"—repositories where data is stored but unusable. To avoid this, organizations implement governance zones:
- Landing Zone (Raw): Data arrives in native format without transformation
- Refined Zone: Data is cleaned, standardized, and structured for analytical use
- Trusted Zone: Fully validated data ready for production analytics and reporting
Use Cases in Healthcare
That governance structure translates directly into practice. Rural healthcare organizations use data lakes to aggregate provider credentialing data, track HCP retention and recruitment metrics across counties, and ingest SDOH data alongside workforce data for holistic program planning.
Real-World Impact: MHK, serving 7 of the top 10 U.S. health plans, implemented AWS HealthLake and achieved interoperability capabilities within 90 days—saving approximately nine months of engineering time. Client delivery dropped from months to less than one week, with end-to-end response times under 1.5 seconds at petabyte scale.
Similarly, Memorial Sloan Kettering Cancer Center implemented Dremio's data lakehouse platform, reducing data delivery timelines from weeks to hours and scaling from 5 users to 150 across 6 research teams in just over a year.
Other Healthcare Data Storage Structures
Data lakes don't exist in isolation. Healthcare organizations often run warehouses, databases, and lakehouses alongside or instead of lakes. Understanding each structure's role prevents costly mismatches between technology and need.
What is a Data Warehouse in Healthcare?
A data warehouse is a structured, analytics-optimized repository where data is cleaned, standardized, and organized before storage (schema-on-write). This makes it ideal for repeatable reporting, quality benchmarks, financial performance dashboards, and regulatory submissions.
Warehouses offer speed and reliability for known queries—generating monthly quality reports or tracking payer performance—but are less agile when data types change or new sources need quick integration. Warehouses are "expensive and proprietary and can't handle the modern use cases most companies are looking to address", particularly when dealing with unstructured data like imaging files or physician notes.
Cleveland Clinic migrated 25+ years of data from Epic to Snowflake, establishing a centralized Enterprise Data & Analytics office that enabled faster computing, real-time data sharing, and "conversational analytics" for clinicians.
What is a Traditional Database in Healthcare?
Traditional relational databases (SQL-based systems) are optimized for transactional operations: patient scheduling, billing, EHR record updates. They process individual records quickly but fall short when healthcare analytics demands scale, unstructured content, or exploratory flexibility.
For advanced analytics or AI use cases, relational databases hit a wall. They can't cost-effectively scale to petabytes, struggle with imaging files, audio, video, and clinical notes, and offer little room for the kind of open-ended analysis modern healthcare workflows require.
What is a Data Lakehouse in Healthcare?
A data lakehouse is a modern hybrid architecture that combines the flexible, large-scale ingestion of a data lake with the structured querying, governance, and BI capabilities of a data warehouse, with a metadata and governance layer applied on top of raw storage.
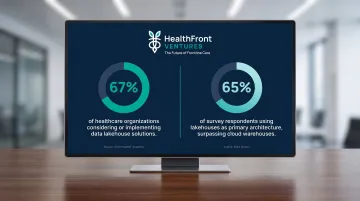
Adoption is accelerating. A 2023 HealthIT Analytics report found that 67% of healthcare organizations are considering or actively implementing data lakehouse solutions, and a 2024 Dremio survey found lakehouses had surpassed cloud data warehouses as the primary architecture for 65% of respondents.
The appeal comes down to consolidation. A single lakehouse can handle:
- AI/ML workloads that need raw, diverse, unstructured data
- BI reporting that needs clean, governed, queryable data
- Operational analytics without duplicating infrastructure or cost
Healthcare Data Lake vs. Other Structures: Which Should You Choose?
Choosing the right data infrastructure requires evaluating:
- Volume and variety of data being managed
- Primary use case (operational reporting vs. AI/predictive analytics vs. transactional processing)
- Internal IT capacity to govern and maintain infrastructure
- Regulatory compliance requirements
Decision Framework: Choose X If...
The right choice depends on where your organization stands today — and where you're headed. Use this as a starting point:
Choose a data lake if:
- You ingest diverse, high-volume data from many sources
- You need flexibility for AI/ML, SDOH, or workforce analytics
- You have governance tooling in place
Choose a data warehouse if:
- Your primary need is reliable, fast reporting on structured data
- You run repeatable BI queries with minimal transformation overhead
- You don't require AI/ML capabilities
Choose a traditional database if:
- Your focus is transactional operations (scheduling, billing, records management)
- You don't need large-scale analytics capabilities
Choose a data lakehouse if:
- You need scalable ingestion, governed analytics, and AI-readiness in one system
- You want to future-proof your architecture without managing separate systems
- You want to reduce operational complexity and infrastructure overhead across analytics, compliance, and reporting
Rural Healthcare Context
Rural organizations with limited IT staff benefit most from outsourced, AI-native data infrastructure that removes the burden of custom builds. Nearly 50% of rural hospitals operate at a financial loss, and IT staffing constraints prevent implementation of even basic cybersecurity measures.
A lakehouse or managed data lake eliminates the need to maintain separate systems for workforce analytics, reporting, and compliance. HealthFront Ventures' AI-Native HCP Workforce Data Warehouses and Lakes are purpose-built for this scenario. They provide outsourced data infrastructure for rural HCP workforce metrics — tracking MDs and NPs/PAs — without requiring internal data engineering teams.
HealthFront Baseline™ is one example of this approach in practice. Launching Q1 2026 with FY25 baseline data metrics across four quantitative measures and one rural county quality measure, it delivers structured workforce intelligence without the overhead of a custom build.
Compliance Considerations
The same infrastructure constraints that challenge rural IT teams also affect compliance readiness — and the governance overhead varies significantly by architecture type. All structures can meet HIPAA requirements, but the effort required differs. Data lakes require more deliberate investment: fine-grained access control via AWS Lake Formation (down to cell, row, or column level), metadata tagging to identify PHI-containing files, and object versioning. Data warehouses rely on column-level security and private subnet VPC isolation. Lakehouses and managed warehouses often include governance frameworks by default, reducing compliance risk.
NIST published SP 800-66 Revision 2 in February 2024, providing updated cybersecurity guidance for HIPAA Security Rule implementation—covering administrative, physical, and technical safeguards for all architecture types.
Real-World Application: Data Infrastructure for Rural Healthcare Workforce Programs
Rural healthcare organizations running HCP retention and recruitment programs face a specific data challenge: workforce data is fragmented across credentialing systems, HR platforms, claims data, and state registries. Generating a unified, actionable view of provider supply, retention rates, and workforce gaps using traditional databases or unmanaged spreadsheets is nearly impossible.
The consequences are severe. The scale of the problem makes delayed decisions costly:
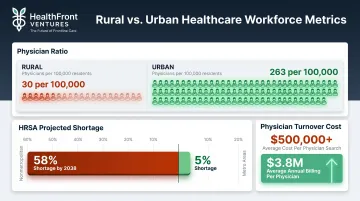
- HRSA projects a 58% physician shortage in nonmetropolitan areas by 2038, versus 5% in metro areas
- Rural areas have approximately 30 physicians per 100,000 people, compared to 263 in urban areas
- A single physician search often exceeds $500,000 in total costs, while physicians generate an average of $3.8 million in annual billing
The timeline pressure compounds this. Full deployment of a unified data platform across large health systems typically takes 12-18 months — a window most rural organizations can't afford to wait through.
Organizations that move faster see real results. Sanford Health, a multi-state rural health system, deployed ambient listening technology to 250+ physicians and achieved a 14.7% reduction in patient length of stay through virtual neurology consultations, while readmission rates dropped nearly 50%. Appointment connect rates rose from 40% to 56% using agentic AI outreach, and 95% of clinicians reported reduced mental fatigue. None of this was possible without data infrastructure capable of integrating clinical, operational, and workforce data in real time.
A managed, AI-native data lake or lakehouse allows rural healthcare organizations to ingest multi-source workforce data, apply baseline metrics, and surface retention and recruitment insights without building custom infrastructure. HealthFront Ventures' HealthFront Baseline™ — launching Q1 2026 with FY25 baseline data metrics across four quantitative measures and one rural county quality measure — is purpose-built outsourced workforce data infrastructure for this specific context.
Conclusion
There is no universally "best" storage structure. The right choice depends on data complexity, analytics goals, compliance requirements, and internal capacity.
Each architecture has a defined role:
- Data lakes prioritize flexibility and AI-readiness for unstructured, high-volume data
- Data warehouses deliver consistent, reliable reporting from structured sources
- Lakehouses combine both, offering the most versatile foundation for modern healthcare analytics
- Databases handle real-time transactional needs at the point of care
The deciding factor isn't which technology sounds most advanced — it's which structure supports the specific outcomes your organization needs to measure and act on.
For rural healthcare organizations executing state-level transformation initiatives, the data infrastructure decision carries direct operational consequences. The wrong foundation means workforce and patient data sits unused — collected but never converted into retention plans, recruiting strategies, or provider coverage decisions.
Building and maintaining custom data infrastructure is rarely feasible at the rural health scale. Outsourced solutions designed specifically for HCP workforce analytics offer a practical path to data-driven planning without the cost or technical overhead of building from scratch.
Frequently Asked Questions
What is a data lake and why is it important?
A data lake is a centralized repository storing raw data in any format—structured, semi-structured, and unstructured. Its importance lies in enabling healthcare organizations to consolidate diverse data sources (EHR, claims, workforce, SDOH) for advanced analytics and AI without requiring pre-transformation.
Can a data lake store unstructured data?
Yes—storing unstructured data is one of a data lake's core strengths. Examples in healthcare include physician notes, radiology reports, voice recordings, imaging files, and provider contract documents. Traditional databases and warehouses struggle to store and analyze these data types cost-effectively.
Why use a data lake instead of a database?
Databases are optimized for transactional operations on structured records—scheduling, billing, EHR updates. Data lakes are designed for large-scale storage of diverse data types and support analytics and AI workloads that databases cannot handle cost-effectively at petabyte scale.
Do I need a data lake or a data warehouse?
Choose a data warehouse for structured reporting and BI on known queries. Choose a data lake for flexible, large-scale ingestion and AI/ML workloads on diverse data. A data lakehouse combines both in one architecture—the right fit when your organization needs flexible ingestion and structured reporting without managing two separate systems.
What is the difference between a data lake and a data warehouse for AI?
Data lakes are preferred for AI because they store raw, diverse data needed for model training without pre-defined schema constraints. Warehouses store pre-processed, structured data optimized for reporting—not model training, which depends on access to unstructured and semi-structured inputs in their native formats.


